WorldScape Policy: Generalizable Robotic Learning via a Foundation World Model
Why WorldScape Policy?
While existing Vision-Language-Action (VLA) models often demonstrate impressive results in controlled laboratory settings, they frequently struggle in the real world when faced with dynamic lighting, shifting backgrounds, and cluttered environments. To this aim, the Manifold AI team officially releases WorldScape Policy, offering a fundamentally different solution: converting a powerful Foundation World Model directly into a generalist robotic planner. This marks a new paradigm shift—the dawn of the World-Action Model.
Many conventional VLA models process reasoning primarily in the language space, which makes them fragile when encountering out-of-distribution visual states (like novel lighting or unseen background). World models, however, provide a highly promising alternative: continuously predicting and planning directly within high-dimensional visual spaces.
Yet, transforming a generative world model into an executable control policy is non-trivial. Previous video-generation-based methods typically rely on a disjointed two-stage pipeline: first predicting future video frames, then deriving actions using an inverse dynamics model. This disjointed design not only suffers from severe compounding errors but also requires tedious re-calibration for different robot embodiments.
WorldScape Policy shatters this bottleneck. Built upon our proprietary embodied foundation world model, WorldScape, it utilizes a unified Mixture-of-Transformers (MoT) architecture to achieve end-to-end joint modeling of video, depth, and actions under a unified flow-matching objective, bypassing compounding errors entirely.
Besides, to overcome the bottleneck of embodiment data supervision, an automated data filtering and annotation pipeline is proposed, which converts large-scale first-person human videos into interleaved "instruction-action" segments and mixes them with cross-embodiment robot demonstration data.
01 Core Innovation
WorldScape Policy isn't merely a patch to existing policies; it's a bottom-up architectural and data-flywheel reconstruction:
Innovation 1: Foundation World Model Pre-training Imparts Endogenous Spatial Reasoning
Unlike standard video generation models—which lack real-time interactivity, spatial consistency, and physical realism—the WorldScape foundation model is designed specifically for embodied agents. Through a spatial-consistency-enhanced autoregressive distillation framework, it acquires robust endogenous spatial reasoning and predictive capabilities, maintaining stable action-following ability while ensuring high interactive efficiency.
\[ \underbrace{\pi_{p}(\mathbf{o}_{s:s+L}, \mathbf{d}_{s:s+L}, \mathbf{a}_{s:s+L} \mid \mathbf{o}_{s}, \mathbf{d}_{s}, i, \mathbf{q}_{s})}_{\text{WorldScape Policy}} = \underbrace{\pi_{v}(\mathbf{o}_{s:s+L} \mid \mathbf{o}_{s}, i, \mathbf{q}_{s}) \, \pi_{v}(\mathbf{d}_{s:s+L} \mid \mathbf{d}_{s}, i, \mathbf{q}_{s})}_{\text{WorldScape Foundation Model}} \underbrace{\pi_{a}( \mathbf{a}_{s:s+L} \mid \mathbf{o}_{s:s+L}, \mathbf{d}_{s:s+L}, \mathbf{q}_{s})}_{\text{IDM}} \]
Innovation 2: Unified "Video-Depth-Action" Modeling Eliminates Compounding Errors
Abandoning the two-stage paradigm, WorldScape Policy optimizes a unified Flow-Matching objective. It simultaneously predicts future visual trajectories and denoises continuous action chunks. This tight video-action alignment ensures the policy plans directly in the world model's predictive feature space.
Furthermore, to empower the robot with true 3D spatial reasoning for contact-rich manipulation, we inject Depth Positional Embedding (DPE) into multimodal tokens, jointly optimized via our multi-task objective incorporating 3D spatial consistency:
\[ \mathcal{L} = \mathcal{L}_{\text{diff}} + \alpha \mathcal{L}_{\text{3D}} \]
\[ \mathcal{L}_{\text{diff}} = \mathbb{E}_{t, \mathbf{z}_0} \left[\left\|\mathbf{v}_\theta(\mathbf{z}_t, t) - \mathbf{v}_t \right\|_2^2 \right], \]
\[ \mathcal{L}_{\text{3D}} = \frac{1}{K} \sum_{k=1}^{K} \left(\| \hat{\mathbf{D}}_k - \mathbf{D}_k \|_2^2 + \lambda \| \hat{\mathbf{I}}_k - \mathbf{I}_k \|_2^2 \right). \]
Innovation 3: Human-in-the-Loop Post-training for Closed-loop Mastery
To bridge the gap between open-loop predictions and real-world execution, we introduce an Advantage-Conditioned Human-In-The-Loop (HITL) learning paradigm. By leveraging DAgger-style on-policy data collection combined with real-time value prediction, the model effectively corrects execution errors and dramatically improves closed-loop performance.
Innovation 4: Automated, Scalable "Embodied Data Pyramid"
How do we overcome the scarcity of robot-specific data? We establish an automated curation pipeline that converts massive, unstructured egocentric human videos into strictly interleaved "instruction-action" sequences. Mixed with cross-embodiment robot demonstrations and fine-tuning teleoperation data, it forms our Embodied Data Pyramid, naturally scaling the model's generalized manipulation capabilities.
02 Stringent Real-world & Simulation Testing
Against extreme perturbations, WorldScape Policy exhibits overwhelming robustness and transfer efficiency:
-
Performance Leap: Conquering Long-horizon Tasks
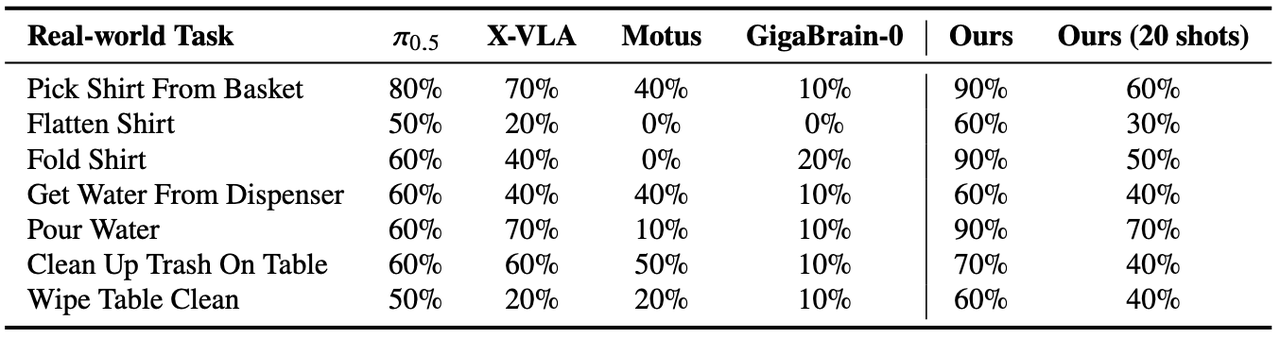
In highly complex tasks like "Folding Clothes" or "Flattening Shirts," WorldScape Policy vastly outperforms previous VLA and two-stage video predictive policies. The precise alignment of visual dynamics and action generation guarantees high-fidelity, dexterous bimanual manipulations on the PIPER platform.
-
Few-Shot Generalization: From Zero to Mastery
Traditional methods severely struggle when encountering unseen tasks under few-shot constraints. By contrast, leveraging the rich physical priors learned during cross-embodiment pre-training, WorldScape Policy achieves rapid few-shot adaptation to novel tasks with minimal demonstrations, significantly cutting down deployment costs.
-
Efficiency King: 10x Training Acceleration
Empowered by the general physics commonsense from the foundation model, our policy slashes fine-tuning requirements. WorldScape Policy converges to optimal success rates with remarkably fewer fine-tuning steps compared to baseline methods requiring tens of thousands of steps.
Table 1: Real-world experiment results of robotic manipulation tasks.
03 Academic Implication
World models must not only "look good" but also "work well".
“We demonstrate that foundation world models are not just capable of generating physically compliant videos; they represent a superior paradigm for general robot learning.”
The release of WorldScape Policy marks the evolution of world models from passive "spectators" (video generators) into active "participants" (action controllers). By harmonizing predictive visual dynamics with geometric-aware conditioning (Depth), it illuminates a highly promising path toward solving the core bottlenecks of data efficiency and embodiment generalization in embodied AI.
04 Conclusions
The Next Step Towards General Embodied Intelligence
WorldScape Policy proves that translating generative world models into executable robot policies is not only possible, but it yields overwhelming advantages in robustness and generalizability. This is not the end goal, but the true dawn of the "World Model Era" for embodied intelligence.